 荐爱小站
荐爱小站随着二维码的越来越普及对一些网站服务会使用到“扫码登录”功能,特别是在 PC网页端,那么是如何实现网站扫码登录的呢?这里简单说一下基本原理。
扫码登陆的实现需要手机端的服务器和 Web端的服务器配合实现。大致分为以下几步:
步骤一:网页端请求登陆二维码
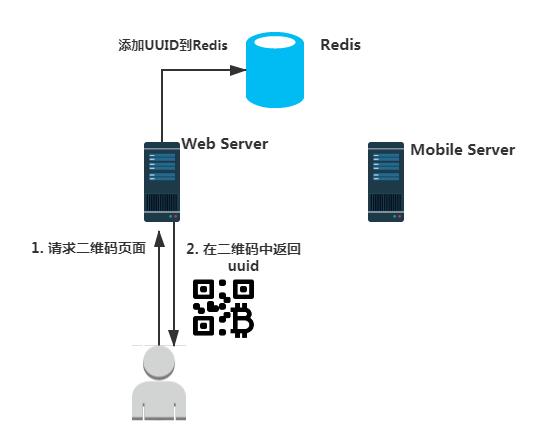
要实现网页版的扫码登陆,用户必须先要请求一个登陆的二维码。Web端的服务器收到用户申请登陆二维码的请求后,会随机生成一个uuid(这个uuid作为页面的唯一标识符),并且会将这个uuid当做一个键值对的key存入后台Redis。存入Redis的这个键值对的value是什么我们待会再说。
需要注意的是存入Redis的键值对必须设置一个过期时间,不然的话拿着这个uuid登陆一次后就一直处于登陆状态了。
当浏览器端拿到Web服务端返回的二维码信息后,解析其中的uuid,并拿这个uuid不断去后台轮询是否已经登陆成功。如果后台已经登陆成功,Web端就自动跳转到登陆成功页面。不然的话会一直轮询,直到二维码失效(这里我们发现给二维码设置有效时间真的很有必要,如果二维码没有有效时间的话,会不断的轮询后台,给后台造成很大的压力)。
那么上面的关键点是Web端服务器是怎么判断用户是否已经扫码登陆成功过的呢? 请看下面的步骤。
步骤二:手机端将用户id存入Redis
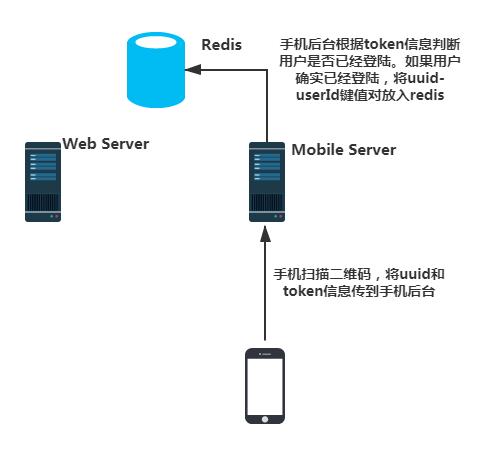
用户请求到二维码后,就开始拿出手机,打开相应的App扫描二维码。扫描过程中手机会将uuid和手机端登陆后获得的token信息一起提交到手机端服务器。
手机端服务器会先拿token信息判断这个用户是否合法,是否已经正常登陆。如果判断已经正常登陆,那么会将这个用户的userId和提交过来的uuid当做一个键值对(uudi-userId)存入Redis。这边回答了步骤一种留下的问题。
简单来讲手机端做的工作就这么多。让我们继续回到Web端。
步骤三:web端轮询成功
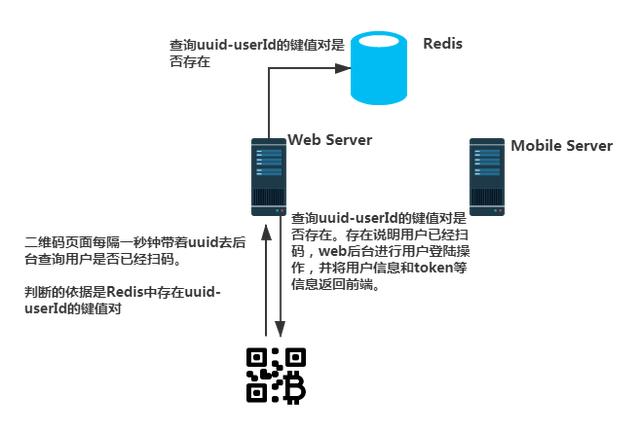
步骤一中讲到二维码登陆页会不停的轮询是否登陆成功。这边的依据就是Redis中存在uuid-userId键值对。如果这个键值对已经存在,说明手机端已经扫码登陆过。
Web端服务器一旦判断到手机端已经扫码登陆过,就可以拿着userId进行登陆。并将必要的用户信息和token信息返回Web前端。至此Web端登陆成功。
小结
本文只是记录了一个扫码登陆的简单版本,但是也能描述扫码登陆的大致原理。实际开发过程中应该还是有许多细节需要考虑,比如安全问题等。
来源作者:写代码的木公
转载请注明链接地址:荐爱小站 » 现在流行的网站扫码登录原理简单解析说明
 多功能 WordPress 图片水印插件:image-watermark(汉化版)
多功能 WordPress 图片水印插件:image-watermark(汉化版)
 彩色短代码功能在 WordPress 上非插件的实现方法
彩色短代码功能在 WordPress 上非插件的实现方法 我的 WordPress 固定链接设置优化的方法记录
我的 WordPress 固定链接设置优化的方法记录










